정렬 알고리즘 - 선택 정렬(Selection sort)
최솟값과 맨 앞의 값을 서로 자리 바꿈으로써 정렬함!
선택 정렬(selection sort)은 가장 기본적이면서도 데이터가 정렬되는 동작을 직관적으로 이해하기 쉬운 정렬입니다.
선택 정렬은 우선 아직 정렬되지 않은 데이터를 모두 확인하여 가장 작은 값(최솟값)을 찾습니다.
그 다음 찾은 최솟값과 정렬되지 않은 데이터 중 맨 앞에 위치한 값의 위치를 서로 바꿉니다.
이렇게 최솟값을 찾아 맨 앞에 위치한 값과 그 위치를 바꾸는 작업을 반복적으로 수행함으로써 데이터를 정렬합니다.
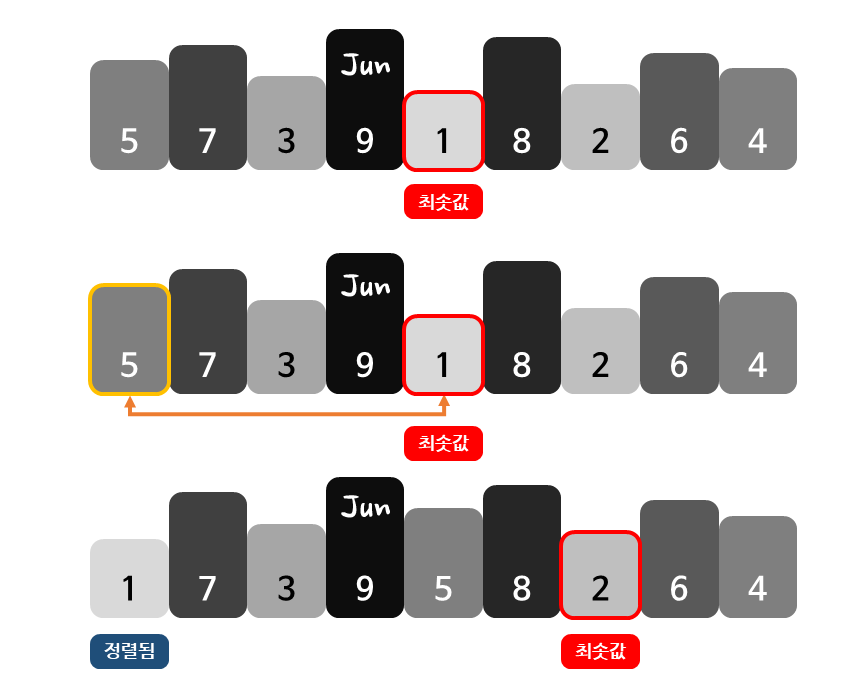
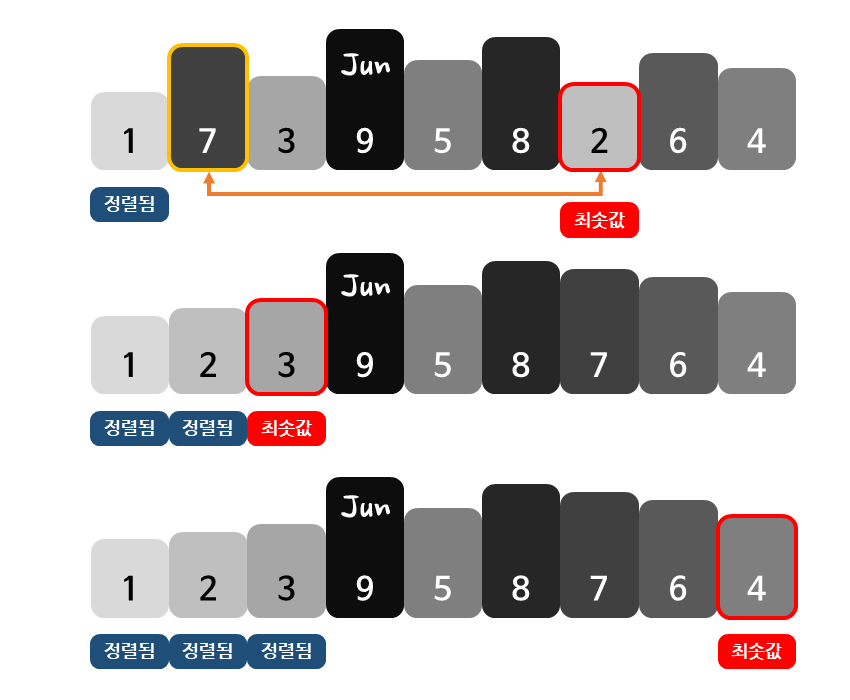
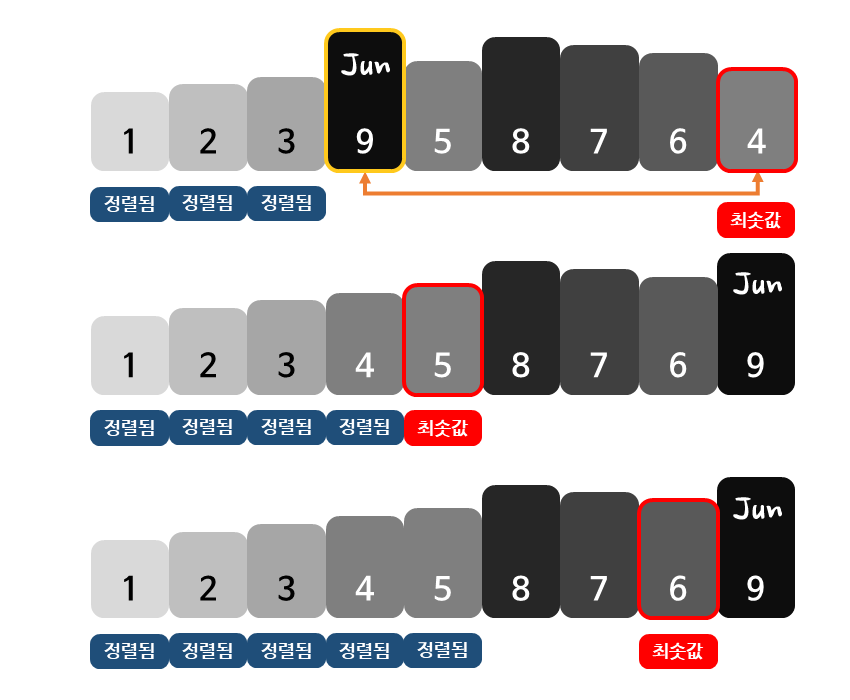
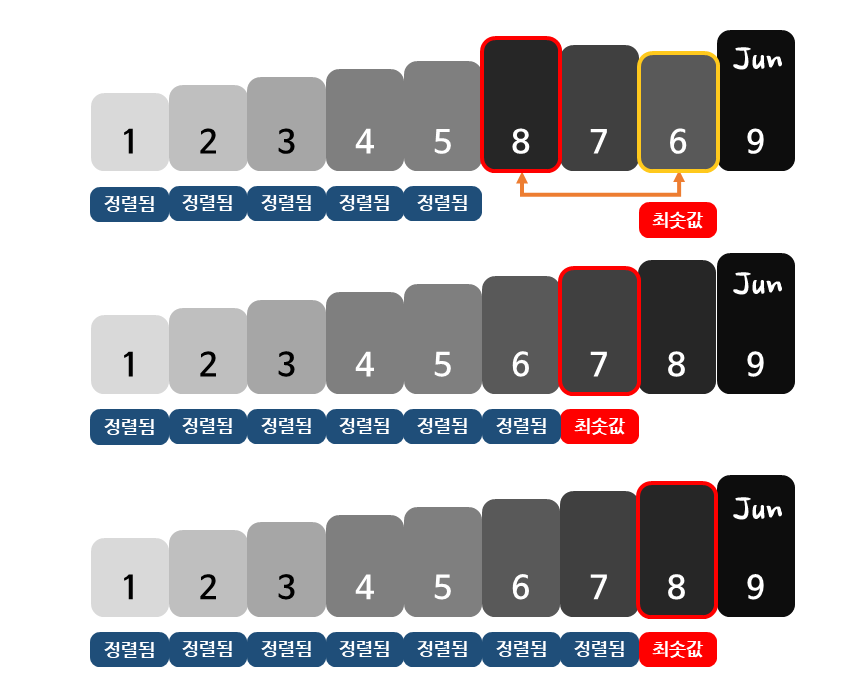
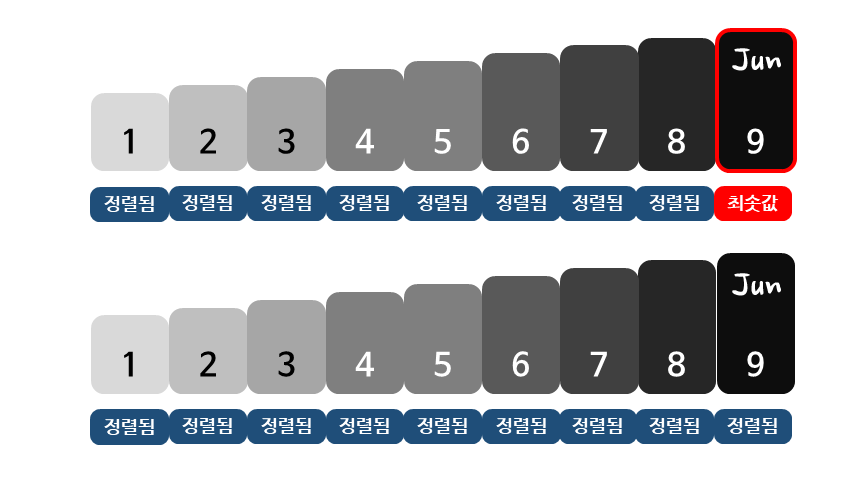
선택 정렬에서 최솟값을 찾는 작업은 맨 처음에는 n개의 데이터를 살펴봐야 합니다. 그 다음 번에는 방금 자리를 바꾼 1개의 데이터를 제외한 n-1개의 데이터를 살펴봐야 최솟값을 찾을 수 있습니다.
이처럼 최솟값을 찾기 위해서는 이미 정렬된 데이터를 제외한 나머지 데이터만을 살펴보면 되므로, n + (n-1) + (n-2) + … + 2 + 1 이 되고, 평균적으로 1/2 × n개의 데이터를 살펴보면 최솟값을 찾을 수 있습니다.
그와 함께 이렇게 찾은 최솟값과 가장 앞에 위치한 데이터와의 자리를 바꾸는 작업이 총 n번 수행되므로, n개의 데이터를 선택 정렬을 사용하여 정렬하는데 걸리는 시간복잡도는 O(1/2 × n × n) = O(1/2 × n2) ≒ O(n2)이 됩니다.
또한, 찾은 최솟값과 가장 앞에 위치한 데이터와의 자리를 바꾸는 작업만으로 정렬을 수행하므로, 선택 정렬의 공간복잡도는 n이 됩니다.
def selection_sort(data):
for i in range(len(data)-1):
min_index = i
# 정렬되지 않은 데이터 중에서 최솟값인 값의 인덱스를 검색합니다.
for j in range(i+1, len(data)):
if data[j] < data[min_index]:
min_index = j
# 정렬되지 않은 데이터의 첫 번째 값과 최솟값을 서로 바꿉니다.
data[i], data[min_index] = data[min_index], data[i]
print(data)
return data
selection_sort([5, 7, 3, 9, 1, 8, 2, 6, 4])
실행결과
[1, 7, 3, 9, 5, 8, 2, 6, 4]
[1, 2, 3, 9, 5, 8, 7, 6, 4]
[1, 2, 3, 9, 5, 8, 7, 6, 4]
[1, 2, 3, 4, 5, 8, 7, 6, 9]
[1, 2, 3, 4, 5, 8, 7, 6, 9]
[1, 2, 3, 4, 5, 6, 7, 8, 9]
[1, 2, 3, 4, 5, 6, 7, 8, 9]
[1, 2, 3, 4, 5, 6, 7, 8, 9]
댓글남기기